





















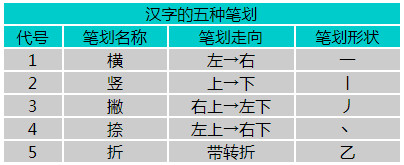
一、五种笔划
什么叫笔划∶在书写汉字时,不间断地一次连续写成的一个线条段叫做汉字的笔划。虽然在汉语中有许多的笔划,但在五笔字型输入法中,汉字的笔划分为横、竖、撇、捺、折五种。为了便于记忆和应用,根据它们使用概率的高低,依次用1,2,3,4,5作为它们的代号,如下图所示∶
在汉字的具体形态结构中,其基本笔划“一、│、乙”常因笔势和结构上的匀称关系而产生某些变形或者一带而变成钩,如“│”变为竖钩等;或者走向多了一些转折,变成“了”“ㄅ”等。另外,一些基本笔划的大小,长短有时也很不一致,于是就派生各种各样的笔划变异。特别是点“、”归并到捺“丶”类中, 类似地提笔“/”和横笔“一”也是等价的。
五种笔划组成字根时,其间的关系可分为四种情况∶
1、 单∶即五种笔划自身
2、 散∶组成字根的笔划之间有一定间距,如三、八、心等
3、连∶组成字根的笔划之间是相连接的,可以是单笔与单笔相连,也可以是笔笔相连。如厂,人,尸,弓等
4、 交∶组成字根的笔划是互相交叉的,如十,力,水,车等。
当然,还会有一种混合的情况,即一个字根的各笔划间,既有连又有交或散,例如“农”、“禾”。
二、汉字的三种字型
根据构成汉字的各字根之间的位置关系,可以把成千上万的方块汉字分三种类型∶左右型,上下型,杂合型。根据汉字的字型,我们也用1─3给出其型状代号,如下表所示∶
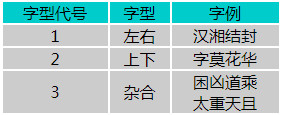
表中最后一种又叫独体字,前二种又统称合体字,两部份合并一起的汉字又叫双合字,三部分合并在一起的又叫三合字。
因为在汉字编取代码时,由于某些汉字字根较少,“信息量不足”,离散不开,所以有必要再补加一个字型信息,而对于由四个部份以上组成或者可以分作四部分的汉字,其信息已够丰富,则不必要再考虑字型信息了,这就是我们今后要取“一二三末”四个字根,且不足四码要追加末笔交叉识别码的原因。
1、左右型汉字
左右型汉字,包括两种情况∶
(1) 在双合字中,两个部分分列左右,其间有一定的矩离如∶ 肚,胡,理,胆,拥等
(2) 三合字中,整字的三个部分从左至右并列∶或者单独占据一边的部分与另外两个部分呈左、右排列,如∶侧、别、谈等
2、上下型汉字
上下型汉字也包括两种情况∶
(1) 双合字中,两个部分分列上下,其间有一定距离,如字,节,旦,看等
(2) 三合字中,三个部分上下排列,或者单占一层的部分与另外两部分作上下排列,如∶意,想,花等
3、杂合──外内型汉字和单体型汉字
三型是指组成整字的各部分之间没有明确的左右或上下型关系者,如∶困,同,这,斗,头等
三、基本字根及其优选
字根,是由若干笔划交叉连接而形成的相对不变的结构叫字根。可理解为字根是组成汉字的基本单位,每一个汉字都是由一个或多个字根拼接而成的。

四、汉字的结构分析
基本字根本身在组成汉字时,按照它们之间位置关系也可以分为四种类型。
1、单:即基本字根本身就单独成为一个汉字,如∶口,木,山,田,马,寸等
2、散:指构成汉字的基本字根之间可以保持一定距离,如∶吕,足,困,汉等
3、连:指一个基本字根连一单笔划,如“丿”下连“目”即成为“自”,连的另一种情况所谓“带点结构”。例∶“勺,术,太”。按规定,一个基本字根之前或之后的孤立点,一律视作是基本字根相连的关系。
4、交:指几个基本字根交叉套迭之后构成的汉字。如∶“农”是由“冖氏”,“申”是由“日丨”等。
综上所述,归纳如下∶
1)基本字根单独成字,在将来的取码中有专门的规定,不需要判断字型
2)属于“散”的汉字,才可以分左右,上下型
3)属于“连”与“交”的汉字,一律属于第三型
4)不分左右,上下的汉字,一律属于第三型
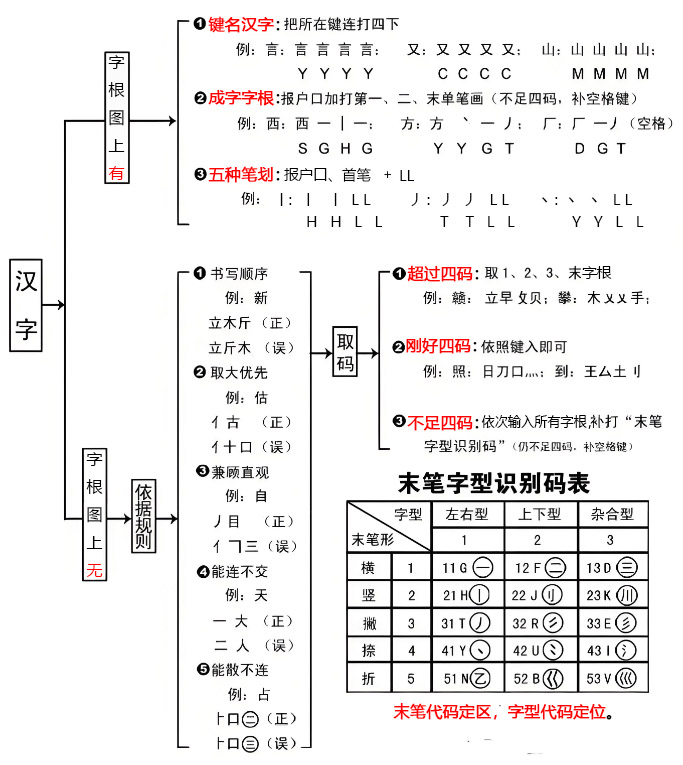
五、汉字的末笔字型交叉识别
对于拆不够四个字根的汉字,要在字根打完后,加上一个末笔字型交叉识码,识别码是由末笔代号与字型代号组合而成,如∶
汉∶43 54 41,末笔代号4,字型代号1 (左右型),(ICY,Y为第4 区第1个键)
字∶45 52 12,末笔代号1,字型代号2 (上下型),(PBF,F为第1 区第2个键)
注意∶1.“键名”及一切成字字根都不用识别码。
如果一个字加了识别码后仍不足四码,则必须补空格。
六、汉字的折分原则
折分原则可归纳为以下四个要点∶
取大优先,兼顾直观,能连不交,能散不连

七、字根分步和字根助记词
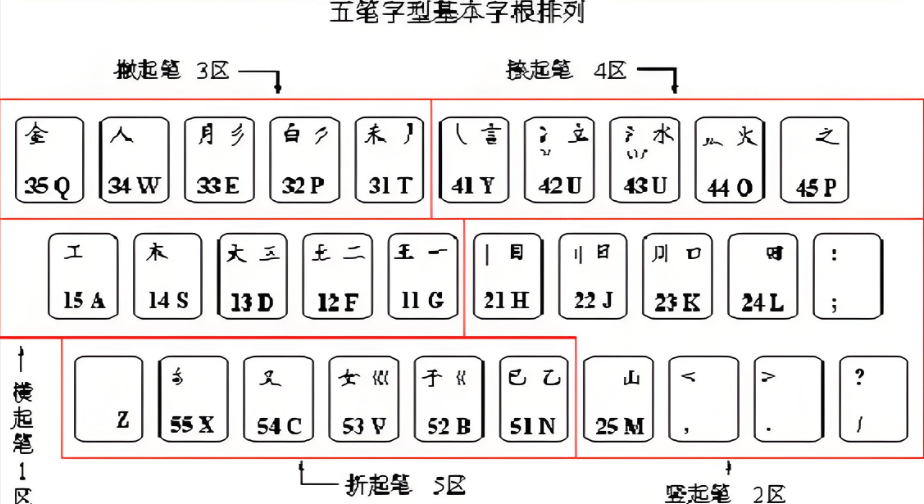
1.键盘键位安排
五笔字型是利用普通的PC键盘进行汉字输入的,所以将PC键盘进行了逻辑化分。化分规则如下:
将26个英文字母键分为五个区域,每个区域为一个区,分别称为1区、2区、3区、4区和5区,在五笔字型中1、2、3、4、5分别代表了横、竖、撇、捺、折,这样1区也可称为横区,2区也可称为竖区,3区也可称为撇区,4区也可称为捺区,5区也可称为折区。每个区就分得5个键,将其称为5个位。那么为了记录方便每个键又可记作:几区几位,可以数字来表示。
如:23,则表示2区3位或竖区3位、
35,则表示3区5位或捺区5位。
如下图所示(说明:由于Z键在标准打字中比较难打,所以五笔字型中将其排除在在5区之外,当然也对其安排了其它用途,参考后文中的学习键Z)
2.字根分步与安排
五笔字型86版中优选了130种基本字根,这么多字根是如何分配至具体的哪个键位上的呢,在这个问题五笔字形遵循了一个大规则(整体分配)与三个小规则(细节调控)。
一个大规则(整体分配)
每一个字根的首笔笔划代码定区,
那么以横开头的字根就被统一的分配到了1区,以竖开头的字根就被统一的分配到了2区,以撇开头的字根就被统一的分配到了3区,以捺开头的字根就被统一的分配到了4区,以折开头的字根就被统一的分配到了5区,所以1区也可称为横区,2区也可称为竖区,3区也可称为撇区,4区也可称为捺区,5区也可称为折区。
一区∶横起笔类 27种,分“王土大木工”五个位;
二区∶竖起笔类 23种,分“目日口田山”五个位;
三区∶撇起笔类 29种,分“禾白月人金”五个位;
四区∶捺起笔类 23种,分“言立水火之”五个位;
五区∶折起笔类 28种,分“已子女又纟”五个位;
三个小规则(细节调控)
通过大规则,每个区也被分配了若干个字根,那么具体的某个字根在本区这5个键位上又如何分配呢?
1>每一个字根的次笔笔划代码定位
如:王
首笔为一,笔划代码为1,所以它被分到了1区之内(即横区)
次笔也为一,笔划代码为1,所以它被分到了1位之上
而1区1位对应的G键,所以字根“王”则分配至了G键之上。
如:土
首笔为一,笔划代码为1,所以它被分到了1区之内(即横区)
次笔也为丨,笔划代码为2,所以它被分到了2位之上
而1区2位对应的F键,所以字根“土”则分配至了F键之上。
如:禾
首笔为丿,笔划代码为3,所以它被分到了3区之内(即撇区)
次笔也为一丨,笔划代码为1,所以它被分到了1位之上
而3区1位对应的F键,所以字根“禾”则分配至了T键之上。
如果所有字根都按上述规则如分布,就会出现某个键上分配的字根很多 ,而某些键分配的字根又太少,甚至分配不到字根,如S键和K键(自行分析)。为了解决这一矛盾,就出现在其它的两个小规则。
2>散笔笔划数量来定位
如:二
首笔为一,笔划代码为1,所以它被分到了1区之内(即横区)
散笔数量为2,所以它被分到了2位之上
而1区2位对应的F键,所以字根“二”则分配至了F键之上。
如:氵首笔为点,笔划代码为4,所以它被分到了4区之内(即捺区)
散笔数量为3,所以它被分到了3位之上
而3区3位对应的I键,所以字根“氵”则分配至了I键之上。
3>移植法
通过上述两种方法,依然使某些键位上分配的字根比较多,所以就用到移植法强制将某些字根从分配比较多的键位上移到分配比较少的键位之上。
如:丁首笔为一,笔划代码为1,所以它被分到了1区之内(即横区)
次笔也为丨,笔划代码为2,所以它应该被分到了2位之上,但2位上的字根比较多。所以强制将其移动到了本区4位上即S键。
如:口
首笔为竖,笔划代码为2,所以它被分到了2区之内(即竖区)
次笔也为乙,笔划代码为5,所以它应该被分到了5位之上,但5位上的字根比较多。所以强制将其移动到了本区3位上即K键。
经过移植法的调整,虽然每个键位上的字根均匀了不少,但规则性也就不那么强了。为了学习与记忆,所以出现了字根助记词。在助记词里包含了所有的经过移植法移植的字根。同时它也比较押韵,多读则会朗朗上口。
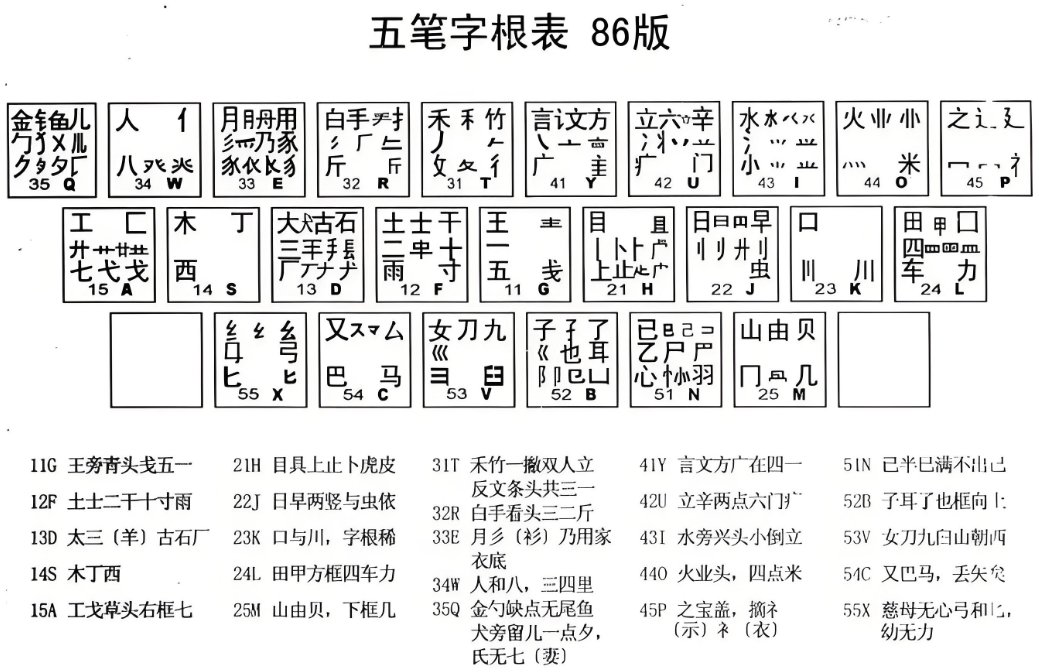
关于字根助记词中每一句中与对应字根的关系,详见视频详解
八、汉字基本输入法
在五笔字根键盘分布图中,有很多字根本身就是标准的汉字,而大多数的汉字虽然没有直接出现在键盘图上,但可以由一个或多个字根组合而成。所以汉字在打字过程中可分有两类,即键盘图上有的汉字与键盘图上没有的汉字。
1、键盘图上有的汉字可以分为三类:
1.键名汉字输入(连击四次)
键名是指各键位组字频度较高,而形体上又有一定代表性的字根,它们中绝大多数本身就是汉字(字根助记词中每一句的第一个字或字根分布图中左上角的字),只要把它们所在键连击四次就可以了。如∶
王∶11 11 11 11 (GGGG)
立∶42 42 42 42 (UUUU)
2.成字字根汉字输入(键名代码+首笔代码+次笔代码+末笔代码)
在每个键位上,除了一个键名字根外,还有数量不等的几种其它字根,它们中间的一部分其本身也是一个汉字,称之为成字字根。(字根助记词中每一句的非第一个字或字根分布图中非左上角的字)
成字字根输入方法为:键名代码+首笔代码+次笔代码+末笔代码
如果该字根只有两笔划,则以空格键结束。例∶
由∶25 21 51 11 (MHNG)
十∶12 11 21 (FGH)
3、五种单笔划的编码为∶
一 11 11 24 24 (GGLL)
丨 21 21 24 24 (HHLL)
丿 31 31 24 24 (TTLL)
丶 41 41 24 24 (YYLL)
乙 51 51 24 24 (NNLL)
2、键盘图上没有的汉字也可以分为三类:
对于键盘没有的汉字先按照拆字规则进行拆分,对拆分的结果分类三种,即超过四码,刚好四码和不足四码
1.超过四码
将汉字拆开后,字根数量多于4个时,按顺序依次输入1、2、3、末字根即可。
例∶
疆 弓 土 一 田 一 田 一 (XFGG)
攀 木 㐅 㐅 木 大 手 (SQQR)
赣 立 早 夂 工 贝 (UJTM)
2.刚好四码
将汉字拆开后,字根数量刚好是4个时,按顺序依次输入1、2、3、4字根即可。
例:
副 一 口 田 || (GKLJ)
给 纟 人 一 口 (XWGK)
到 一 厶 土 刂 (GCFJ)
3.不足四码将汉字拆开后,字根数量不足4个时,依次输入已有字根,再加入五笔字型末笔交叉识别码即可。
五笔字型末笔交叉识别码是指:一个汉字的最后一笔的笔划代定义一个区编号,再用该字的字型编码定义一个位编号。这样就可以知道识别码的区、位编码。进而这个键就是该汉字的识别码。简单的说:末笔定区,字型定位
如∶
汉 氵 又(末笔为捺,捺的编号为4、字型为左右型,编号为1,即4区1位,那么“汉”这个字的的识别码就为:Y)
国∶囗 王 丶 (末笔为捺,捺的编号为4、字型为杂合型,编号为3,即4区3位,那么“国”这个字的的识别码就为:I)
字∶宀 子 (末笔为横,捺的编号为1、字型为上下型,编号为2,即1区2位,那么“字”这个字的的识别码就为:F)
对于汉字的末笔,有部分字比较难以判断,所以规定如下:
A.所有包围型汉字中的末笔,规定取被包围的那一部分笔划结构的末笔
国∶其末笔应取“丶”,识别码为43(I)
远∶其末笔应取“乙”,识别码为53(V)
B.对于字根“刀、九、力、七”,虽然只有两笔,但一般人的笔顺却常有不同,为了保持一致和照顾直观,规定,凡是这四种字根当作“末”而又需要识别时,一律用它们向右下角伸得最长最远的笔划“折”来识别,如∶仇∶34 54 51
化∶34 55 51
九、简码
为了提高输入速度,将汉字完整的五笔编码根据其使用的频率省掉一码、两码或三码。这样就构成简码。
1.一级简码(需特殊记忆)
一级简码是使用频率最高的汉字,由于打字用的键盘上只有25键可用,所以挑出了使用频率最高的25个汉字,根据每个键上字根与高频字间的关系进行排放。虽有一定联系,但仍需特殊记忆。
一 11(G) 地 12(F) 在 13(D) 要 14(S) 工 15(A)
上 21(H) 是 22(J) 中 23(K) 国 24(L) 同 25(M)
和 31(T) 的 32(R) 有 33(E) 人 34(W) 我 35(Q)
主 41(Y) 产 42(V) 不 43(I) 为 44(O) 这 45(P)
民 51(N) 了 52(B) 发 53(V) 以 54(C) 经 55(X)
2.二级简码(省掉后两码)
只需输入完整编码的前两码后补空格,理论上二级简码共有25X25=625个,但实际会少于625个。如∶
吧∶口巴 (23, 54, KC)
给∶纟人 (55, 34, XW)
3.三级简码(省掉后一码)
只需输入完整编码的前三码后补空格。如∶
华∶全码∶人七十= (34 55 12 22, WXFJ)
简码∶人七十 (34 55 12 WXF)
4.词汇编码
(1)双字词
分别取两个字的单字全码中的前面个字根代码,共四码组成,记作:12,12
如∶
机器∶木几 口口 (SMKK)
汉字∶氵又 宀子 (ICPB)
(2)三字词
前两个字各取其第一码,最后一个字取其二码,共为四码,记作:1,1,12
如∶
计算机∶言竹木几 (YTSM)
(3)四字词
每字各取其第一码,共为四码,记作:1,1,1,1
如∶
汉字编码∶氵宀纟石 (IPXD)
光明日报∶小日日扌 (IJJR)
(4)多字词
按“一、二、三、末”的规则,取第一、二、三及最末一个字的第一码,共为四码,记作1,2,3,末
如∶
电子计算机∶日子言木 (JBYS)
中华人民共和国∶口人人囗 (KWWL)
十、“Z”学习码
在五笔输入法中z键称为“万能键”,可代替a-y中的任意一个键。Z键上虽然没有任何字根,但当初学者不熟悉某些汉字的根,键或根时,他们可以通过Z键获得帮助。
在五笔输入法中的Z键,有两个主要功能,一就是代替未知的识别码,二是代替模糊不清或拆分不准的字根。
也就是说在五笔输入法中,一切未知的编码都可以用Z键代替,这样就会增加重码率,如果想提高打字速度最好少用或尽量不用Z键。
 推荐课程
推荐课程
 Word字处理
Word字处理



 推荐文章
推荐文章 500
500 正品保障
正品保障 如实描述
如实描述 专业配送
专业配送 金牌服务
金牌服务 万千信赖
万千信赖

